
Surgical scenarios understanding
Cataracts are the most common cause of vision loss and blindness in the worldwide; the World Health Organization (WHO) has estimated that the number of people with blindness globally is projected to increase from 43.3 million in 2020 to 61.0 million in 2050. A surgical procedure to replace the eye lens with an artificial one when the cataract makes the vision cloudy, usually in geriatrics. Instrument-tissue interaction detection in cataract surgery video is a fundamental problem for surgical scene understanding.
Task 1: Quintuple Detection [instrument bounding box, tissue bounding box, instrument class, tissue class, action class]
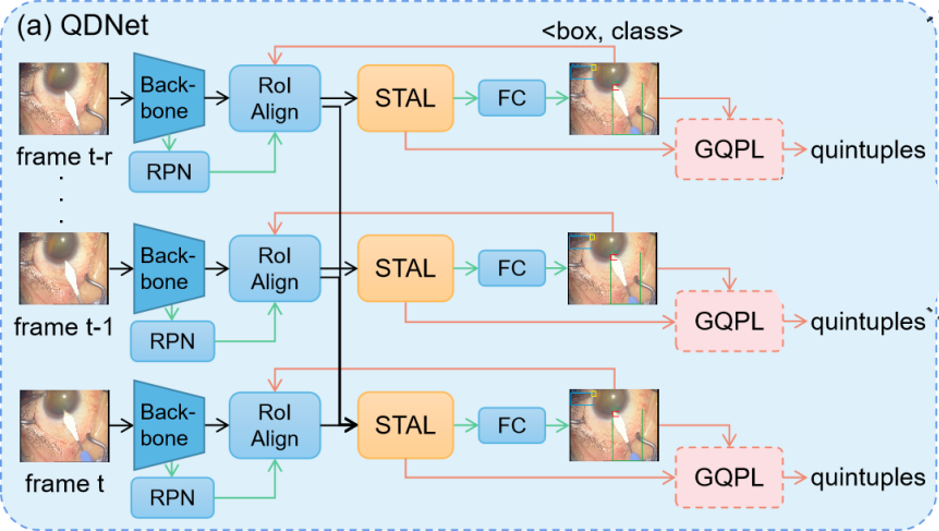
- Instrument-tissue Interaction Quintuple Detection in Surgery Videos (MICCAI2022) We first define instrument-tissue interaction quintuple: [instrument bounding box, tissue bounding box, instrument class, tissue class, action class] For the problem of Quintuple Detection, we propose a Quintuple Detection Network (QDNet), including instrument and tissue detection stage, and quintuple prediction stage.
 The experiment results based on Cataract Dataset are:
The experiment results based on Cataract Dataset are: 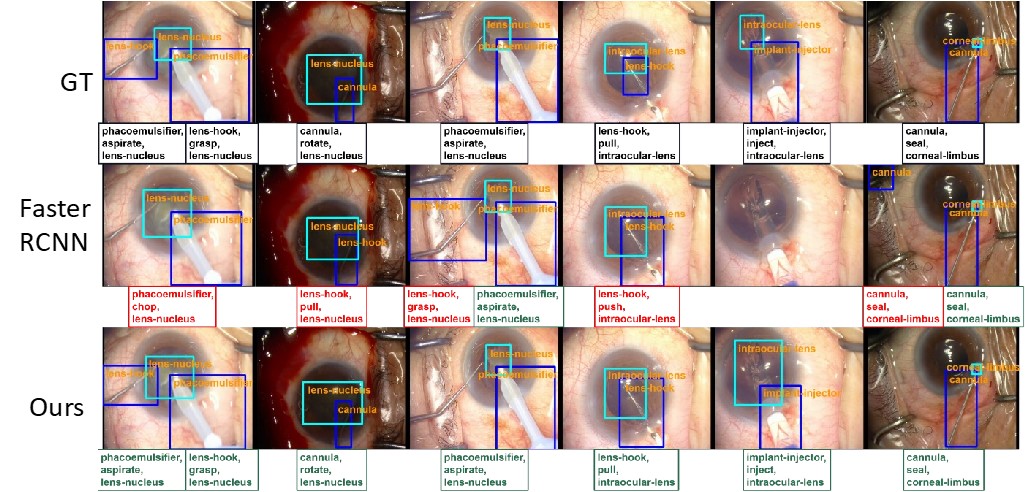
- Instrument-tissue Interaction Detection Framework for Surgical Video Understanding (TMI2024) Instrument-tissue interaction detection task, which helps understand surgical activities, is vital for constructing computer-assisted surgery systems but with many challenges. Firstly, most models represent instrument-tissue interaction in a coarse-grained way which only focuses on classification and lacks the ability to automatically detect instruments and tissues. Secondly, existing works do not fully consider relations between intra- and inter-frame of instruments and tissues. In the paper, we propose to represent instrument-tissue interaction as ⟨instrument class, instrument bounding box, tissue class, tissue bounding box, action class⟩ quintuple and present an Instrument-Tissue Interaction Detection Network (ITID-Net) to detect the quintuple for surgery videos understanding. Specifically, we propose a Snippet Consecutive Feature (SCF) Layer to enhance features by modeling relationships of proposals in the current frame using global context information in the video snippet. We also propose a Spatial Corresponding Attention (SCA) Layer to incorporate features of proposals between adjacent frames through spatial encoding. To reason relationships between instruments and tissues, a Temporal Graph (TG) Layer is proposed with intra-frame connections to exploit relationships between instruments and tissues in the same frame and inter-frame connections to model the temporal information for the same instance. For evaluation, we build a cataract surgery video (PhacoQ) dataset and a cholecystectomy surgery video (CholecQ) dataset. Experimental results demonstrate the promising performance of our model, which outperforms other state-of-the-art models on both datasets.
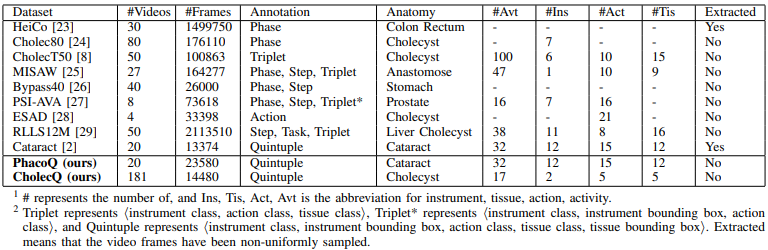
Dataset: We define instrument-tissue interaction quintuple: [instrument bounding box, tissue bounding box, instrument class, tissue class, action class]. The details are listed as
 Please contact Yan Hu (huy3@sustech.edu.cn) about the dataset.
Please contact Yan Hu (huy3@sustech.edu.cn) about the dataset.
- We collect a Cataract Quintuple Dataset based on phacoemulsification. Data: 15 videos for training, 5 videos for test Annotation: class label (12 instruments, 12 tissues, 15 actions), bounding box (12 instruments, 12 tissues)
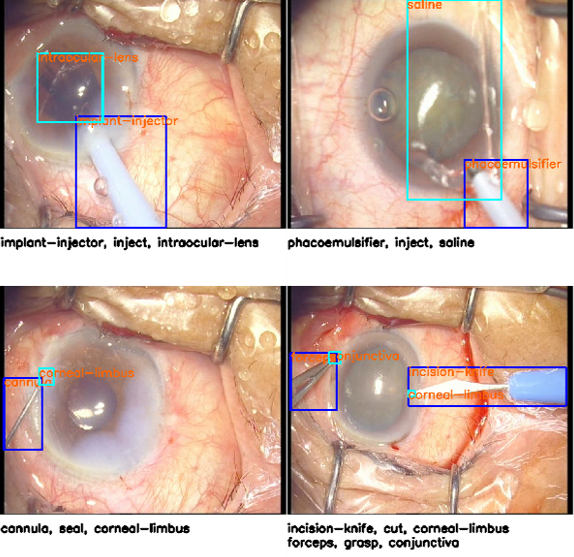
- We also label a Cholecystectomy CholecQ Dataset based on publicly available dataset.
Task 2: Action Detection (coarse-fine-grained representation)
- ACT-Net: Anchor-context Action Detection in Surgery Vidoes (MICCAI2023, Oral) We develop an anchor-context action detection network (ACTNet), to answer the following questions: a) Where actions locate; b) What actions are; c) How confident our model is about predictions
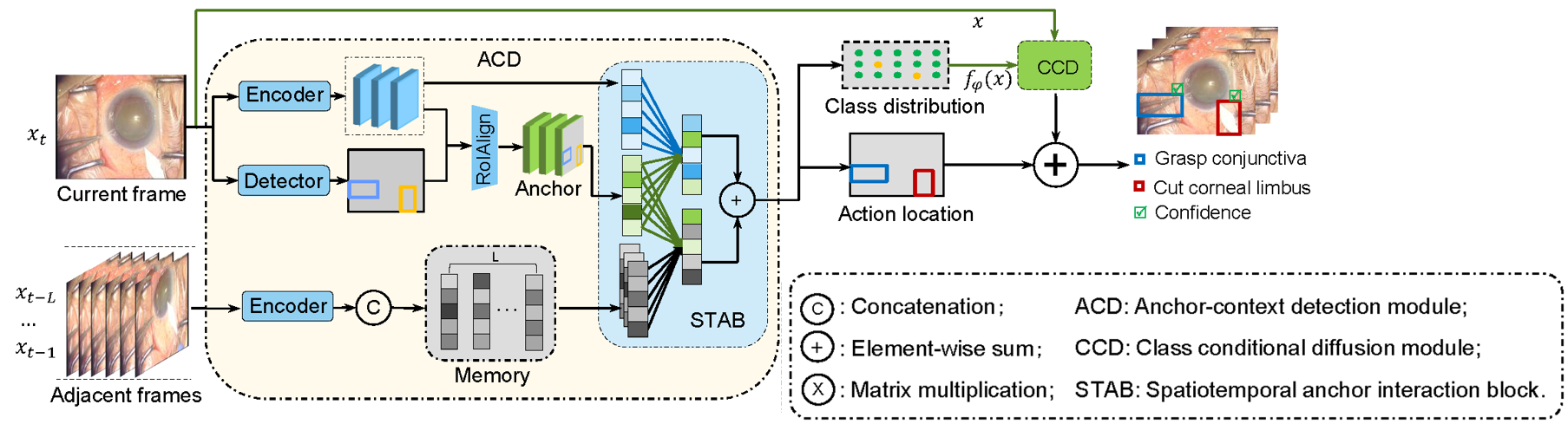 The experiments results are:
The experiments results are: 
Dataset: We make CholecQ dataset publicly available at https://figshare.com/articles/dataset/cholec181_dataset_for_instrument-tissue_interaction_detection_for_surgical_scene_understanding/28194026
Task 2: Multi-granularity surgical scene understanding code at https://github.com/Aurora-hao/HCT